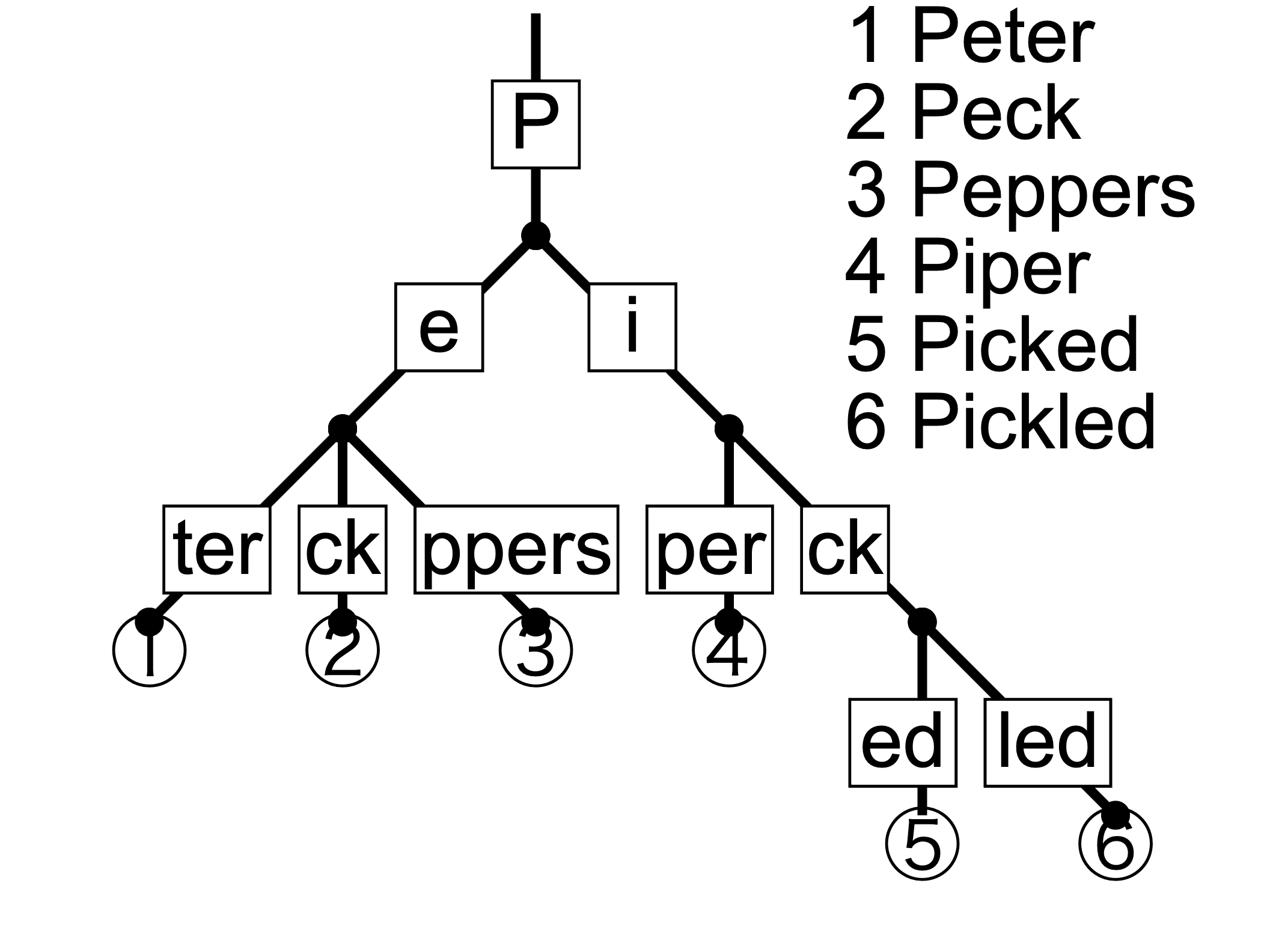
breaking down SGLang: how a 1968 data structure made LLM inference 6x faster

Every time you send a message to an LLM, most of the computation is redundant. the GPU recomputes key-value tensors it already computed seconds ago for a different request. in production serving, 80%+ of input tokens are identical to tokens the system just processed for someone else.
SGLang, the open-source inference engine running on 400,000+ GPUs today, fixes this with a data structure from 1968: the radix tree. first invented for text retrieval, later adopted by networking engineers for IP routing, and now repurposed for the single most important optimization in LLM serving: prefix caching.
Let’s build up a first-principles understanding of what’s actually happening here.
the KV cache, from first principles
to understand why prefix caching matters so much for serving LLMs really fast, you need to understand what the KV cache is and why it usually takes up a lot of GPU memory.
a transformer generates tokens one at a time. to generate each new token, the model runs self-attention: each token looks at every previous token to figure out which ones are relevant. the math for attention is:
Attention(Q, K, V) = softmax(QK^T / sqrt(d_k)) * V
(play around with this visualization build intuition on this formula)
for each token, a useful heuristic is that the model computes three vectors:
Q (Query): “what am i looking for?”
K (Key): “what do i contain?”
V (Value): “what information do i hold?”
to generate a new token, the model computes a new Query vector and compares it (via dot product) against the Key vector of every previous token. the result is used to aggregate the Value vectors. this is how the model decides that when writing “the cat sat on the ___”, the token “mat” should attend heavily to “cat” and “sat”.
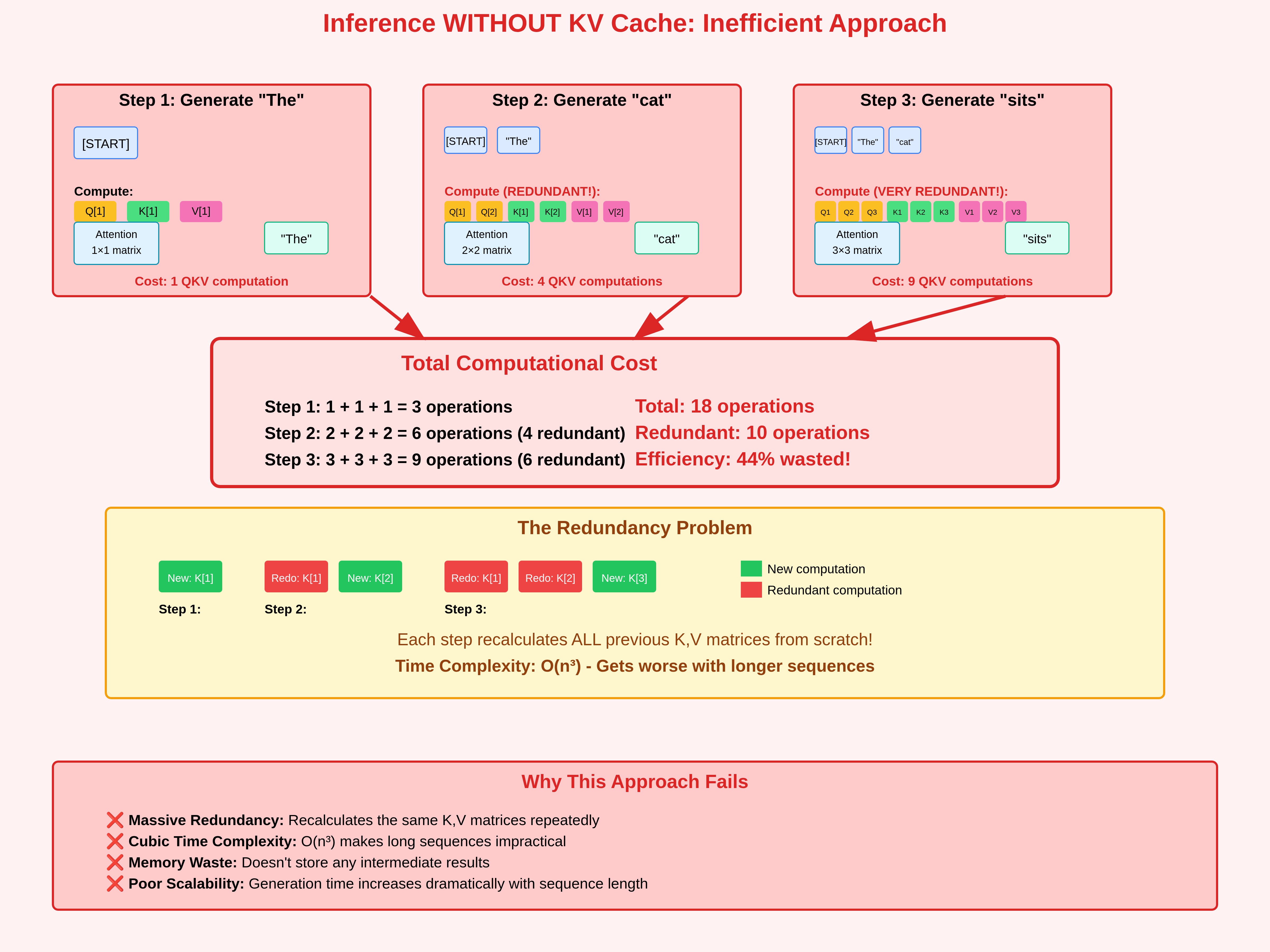
without a KV cache, generating each new token recomputes K and V for every previous token. the highlighted regions are
redundant computation. (source: kapilsharma.dev)
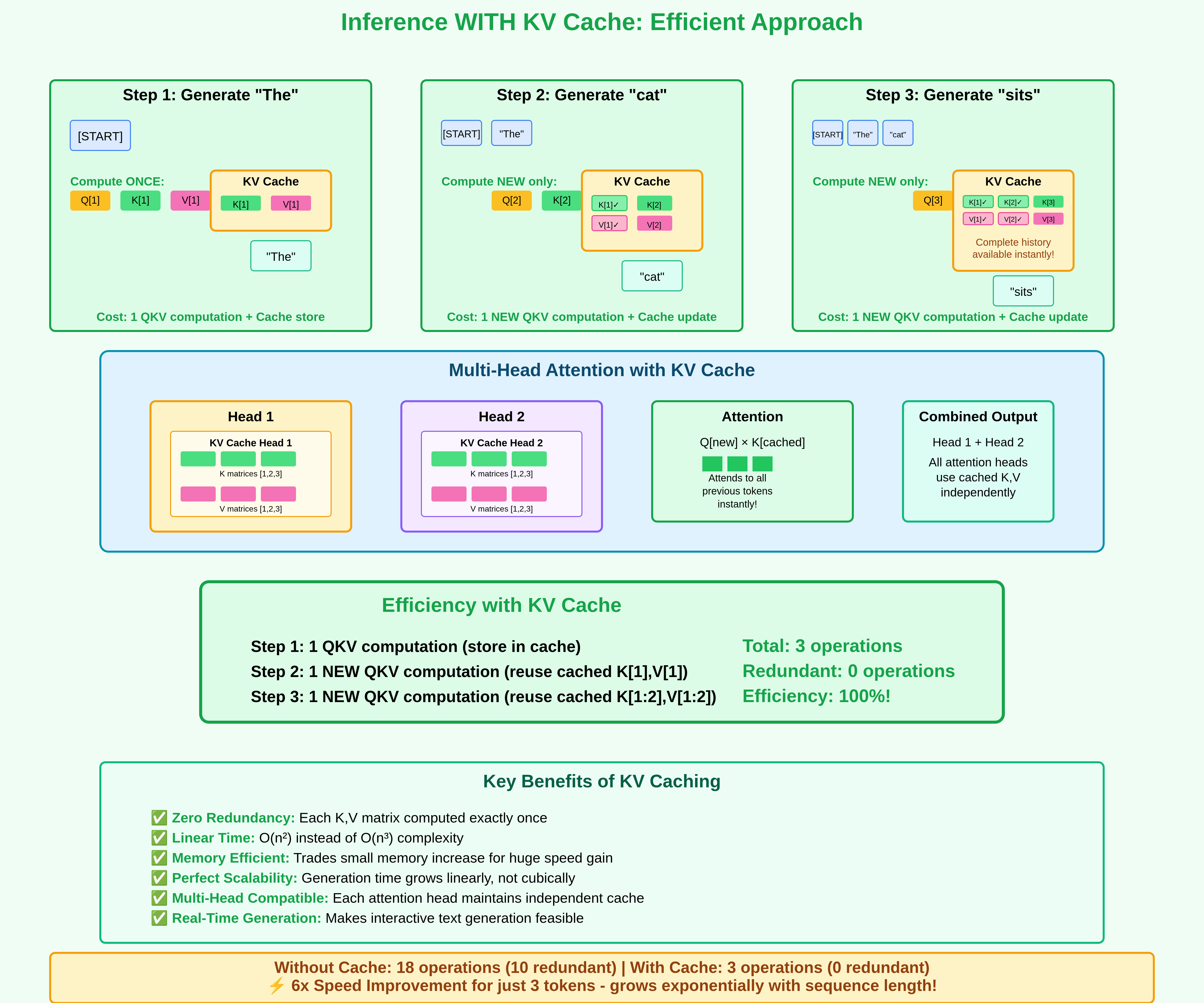
the insight of the KV cache is that when generating the 1000th token, the Key and Value vectors for tokens 1 through 999 are mathematically identical to what they were when generating the 999th token. without a cache, the model would recompute K and V for all 999 previous tokens from scratch. this would be O(N^2) total work for an N-token sequence.
instead, the KV cache stores these tensors. compute K and V once, keep them in GPU memory, and reuse them for every subsequent token. this collapses O(N^2) to O(N). it’s one of the most important optimizations in LLM inference, alongside other great discoveries such as FlashAttention.
if you want to run through a visualization with the talented Kapil Sharma, here’s a great blog post about this.
how big is the KV cache normally? it’s actually
KV cache (bytes) = 2 x layers x kv_heads x head_dim x seq_len x bytes_per_element
the “2” is because you store both K and V. let’s run the math for llama 3.1 70B at FP16:
2 x 80 layers x 8 kv_heads x 128 head_dim x seq_len x 2 bytes
at 8K context: 2 x 80 x 8 x 128 x 8,192 x 2 = 2.56 GB per request.
at 128K context: 2 x 80 x 8 x 128 x 131,072 x 2 = 40 GB per request.
an H100 has 80 GB of HBM. the model weights for llama 70B at FP16 are about 140 GB, so you need at least 2 GPUs just for weights. on an 8-GPU node (640 GB total), after loading weights, the remaining memory is all KV cache. at 2.56 GB per request with 8K context, that’s roughly 200 concurrent users. but at 128K context, it’s about 12.
KV cache is one of the main reasons long-context inference is expensive.
the redundancy problem
what makes this KV problem even more interesting for systems software is that most of those KV cache bytes are redundant across requests too!
let’s think about how LLMs are actually used.
every API call to a chatbot starts with the same 500-2000 token system prompt. maybe something like “you are a helpful assistant. here are your instructions...” every single request recomputes the exact same K and V tensors for those tokens.
another case of this is few-shot examples. a code assistant that sends 10 examples before every query shares those examples across every request.
agent loops. an agent’s tool definitions, goal description, and accumulated observation history form a massive prefix. Manus AI reports 100:1 input-to-output ratios in agentic workloads. this means 99% of the tokens are prefix!
and more…
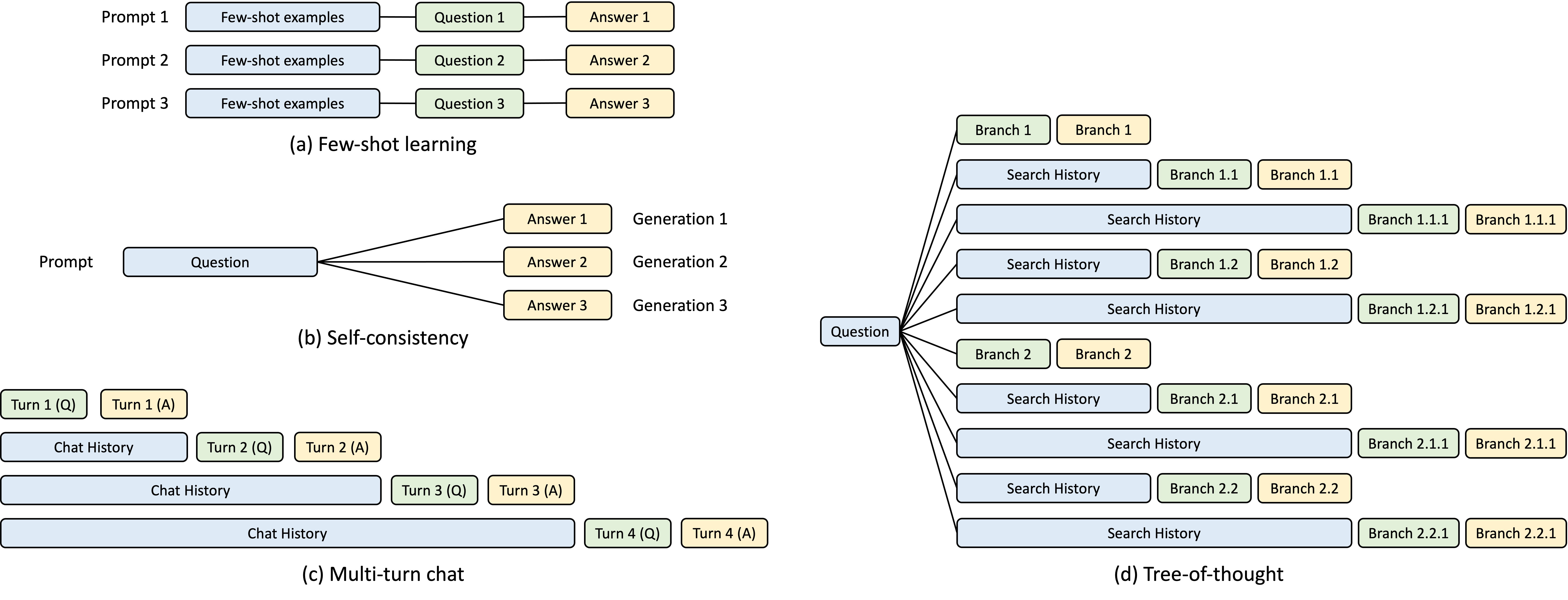
so the question becomes: how do you find and reuse shared prefixes efficiently?
this is a longest-prefix-match problem
let’s state the problem precisely though.
when a new request arrives, the serving system has a token sequence (the full prompt). it needs to answer:
“what is the longest prefix of this token sequence for which i already have computed KV cache tensors in GPU memory?”
the answer determines where prefill starts. if the first 2,000 tokens match a cached prefix, the model skips straight to token 2,001 and only computes K and V for the remaining tokens.
the stored data is:
keys: sequences of token IDs (integers)
values: GPU memory page indices where the K/V tensors live
query: longest-prefix match. not exact match. the longest stored key that is a prefix of the incoming sequence.
if you’ve studied computer networking, this should sound familiar. this is because it’s exactly the same problem that IP routers solve.
when a packet arrives at a router, the router has a forwarding table of IP prefixes (e.g., 192.168.0.0/16, 10.0.0.0/8). it needs to find the longest prefix that matches the destination IP address. the match determines where to send the packet. this is called longest-prefix match, and networking engineers solved it decades ago using a data structure called a Patricia trie, a type of radix tree.
Donald Morrison invented PATRICIA (Practical Algorithm To Retrieve Information Coded In Alphanumeric) in 1968 and published it in the Journal of the ACM. the key finding is that you can eliminate single-child nodes from a trie by storing sequences on edges instead of individual characters on nodes. networking engineers adopted it for IP routing. the Linux kernel today uses a radix tree for its page cache (managing which disk pages are in memory, another prefix-matching problem).
SGLang uses the radix tree for KV cache management. the problem is structurally identical: longest-prefix match over sequences, with associated data at each prefix, and the need to efficiently insert, lookup, and evict entries.
why exactly do hash tables fail at this?
the first instinct for any caching problem from CS 101 is to just use a hash table. but hash tables can only answer “do i have this exact key?” they cannot answer “what’s the longest key that is a prefix of my query?”
vLLM, the other major open-source inference engine, uses a hash-table-based approach called Automatic Prefix Caching (APC). it divides the KV cache into fixed-size blocks (typically 16 tokens per block) and hashes each block. the hash for block N includes the hash of all previous blocks (chained hashing), creating a unique identifier for each block’s position in the sequence.
this works, but it has structural limitations. mainly (1) block-level granularity and (2) no structural prefix awareness.
(1) block-level granularity. two requests sharing 17 tokens can only reuse the first 16-token block. the 17th token falls in a partial block that can’t be matched. with a radix tree, all 17 tokens are reusable.
(2) no structural prefix awareness. a hash table stores entries independently. it has no concept of “this entry is a prefix of that entry.” when you need to evict cache entries under memory pressure, you can’t distinguish between evicting a shared prefix (used by 50 requests) and evicting a unique suffix (used by 1 request). you’d need external bookkeeping to track prefix relationships, which is exactly what a tree encodes structurally.
vLLM’s V1 engine (default since early 2025) significantly improved APC performance, bringing overhead to under 1% and enabling it by default. the throughput gap between vLLM and SGLang has narrowed by a lot.
the radix tree, from first principles
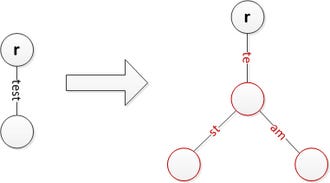
a trie (prefix tree) is a tree where each edge is labeled with a single character (or token). a path from root to any node spells out a prefix. to look up “hello”, you follow edges h → e → l → l → o. every string sharing a prefix shares a path from the root.
tries have an important limitation: memory waste from single-child chains. the path for “cartridge” creates 9 separate nodes even though there’s zero branching for 6 of them. each node might allocate space for the entire alphabet of possible children, most of which are empty.
a radix tree fixes this with path compression. any chain of single-child nodes is collapsed into one node with the edge labeled by the entire sequence. so instead of 9 nodes for “cartridge”, you get one node with edge label “cartridge”. if you also store “carpet”, the tree splits: a shared “car” edge, then two children: “pet” and “tridge”.
this is what Morrison described in 1968. the formal name is PATRICIA (Practical Algorithm To Retrieve Information Coded In Alphanumeric), published in the Journal of the ACM.
here’s what a radix tree looks like for four strings:
root
└─ [car]
├─ [pet] → “carpet”
├─ [tridge] → “cartridge”
├─ [e] → “care”
└─ (end) → “car”you see 5 nodes instead of 14. the invariants:
1. no two edges from the same node share the same first character
2. no single-child non-terminal nodes exist (maximally compressed)
3. every edge label is non-empty
to lookup: traverse from root, at each node dispatch on the first character of the remaining input, compare against the edge label. if the label is a prefix of the remaining input, continue to the child. if not, stop. the deepest point you reach IS the longest cached prefix. one traversal, O(k) where k is the key length.
to insert an element: traverse like lookup. if you reach a point where the new sequence diverges mid-edge, split the edge. “hello” is cached, “help” arrives. the “hel” prefix becomes a shared node, “lo” and “p” become children.
to delete: remove a leaf. if the parent now has one child and isn’t a terminal, merge parent and child (concatenate edge labels). maintains the compression invariant.
the critical operation for KV cache is longest-prefix match, and the radix tree does it in a single O(k) traversal. a hash table cannot do this at all without trying every possible prefix length.
how SGLang implements it (just read the code)
if you go through SGLang’s source code to understand exactly how the radix tree maps to KV cache management, you’ll see that the entire implementation lives in radix_cache.py in < 1k LOC. let’s talk about it at a high level to keep this interesting, and relate it back to our ideas outlined above. all links in this section are links to actual code in the SGLang repo.
each node in the tree stores the token sequence on its edge, a tensor of GPU memory page indices for the corresponding KV cache, a reference count of active requests using it, and a timestamp for LRU eviction. the tree itself lives entirely on CPU. the actual K/V tensors live on GPU in a paged memory pool (memory_pool.py). the tree is just an index into that pool. this means tree operations (traversal, splitting, eviction) are CPU-side work that overlaps with GPU computation.
when a new request arrives, the scheduler calls match_prefix with the full token sequence. the algorithm walks from root, dispatching on the first token at each level, comparing edge labels against the remaining input. it returns the deepest match plus a concatenated tensor of GPU page indices along the matched path. these indices tell FlashInfer exactly where the cached K/V tensors are. only the unmatched suffix goes through prefill.
after a request completes, the full sequence (prompt + generated output) is inserted. if the new sequence diverges mid-edge from an existing node, the node splits, so “hello world how are you” becomes “hello world “ as a shared parent, with “how are you” and “what time is it” as children. the GPU page indices are divided accordingly. this happens lazily, only when divergence actually occurs.
eviction is where the tree structure really pays off. SGLang maintains a set of evictable leaves (nodes with no children and no active requests). under memory pressure, it pops the least-recently-used leaf, frees its GPU pages, removes it from the tree, and checks if the parent is now a childless, unreferenced leaf too. if so, eviction cascades upward. so a system prompt shared by 50 conversations has 50 children. it cannot become a leaf until all 50 are evicted. shared prefixes survive naturally through tree topology, not external bookkeeping.
the scheduler sorts pending requests by matched prefix length (longest-first), which is equivalent to a DFS traversal of the tree. this achieves ~96% of the theoretically optimal cache hit rate. for multi-GPU deployments, a Rust-based router maintains an approximate radix tree per worker and routes each request to the worker with the longest matching prefix. the v0.4 LMSYS blog reports this improved cache hit rate from 20% to 75% on a shared-prefix workload across 8 H100s, yielding 1.9x throughput.
radix trees are awesome!
SGLang now runs on 400,000+ GPUs worldwide, generating trillions of tokens daily. it powers xAI (Grok), Microsoft Azure (DeepSeek on MI300X), Alibaba Cloud, and many others.
Morrison invented PATRICIA in 1968 for information retrieval. networking engineers adopted it years later because IP routing is a longest-prefix-match problem: given a destination address, find the most specific matching route. the Linux kernel uses radix trees for the page cache because managing cached disk pages is also a prefix-matching problem. and now SGLang uses it because KV cache management in LLM inference is, structurally, the same problem again.
when your core operation is to find the longest stored prefix of an input sequence, the radix tree is the only standard data structure that does it in a single O(k) traversal, while simultaneously providing structural deduplication of shared prefixes and safe dependency-aware eviction.